Jednolity System Antyplagiatowy do wymiany
Od stycznia 2016 r. jestem wydziałowym administratorem systemu antyplagiatowego na jednej z większych uczelni w Polsce. Stanowisko to utworzono na wydziale trzy miesiące wcześniej, by spełniać nowy wówczas ustawowy obowiązek: wprowadzania prac dyplomowych do systemu antyplagiatowego, generowania raportów podobieństwa i przekazywania ich kierującym pracami (zwę ich dalej dla uproszczenia zwyczajowo promotorami). Dość szybko się okazało, że niektórzy (na szczęście mniejszość) promotorzy niespecjalnie się tymi raportami przejmują, dlatego administratorowi dodano zadanie wstępnej analizy i interpretacji tych raportów i orzekania nie tyle o plagiacie, ile o istnieniu bądź nieistnieniu błędów cytowania (czyli np. sytuacji, kiedy cytat jest opatrzony jedynie przypisem, a nie jest ujęty w cudzysłów). W sytuacji ich istnienia na naszym wydziale administrator systemu antyplagiatowego stwierdza, że praca wymaga poprawy i dopóki nie zostanie poprawiona, nie może przejść do dalszych etapów procesu dyplomowania.
Raporty podobieństwa plagiat.pl
Wydział podpisał wówczas umowę z firmą plagiat.pl, która wygasła w 2018 r. i ze względu na wprowadzany JSA nie została przedłużona. Przez ostatnie trzy i pół roku przenalizowałem ponad 2 tys. raportów podobieństwa. Sprawdzanie systemem antyplagiatowym raportów do prac na tematy prawne i administracyjne jest dość uciążliwe, trzeba się nauczyć „z daleka” rozpoznawać cytaty z aktów prawnych i nazwy tych aktów, trzeba odróżniać rozbudowane terminy (np. dotyczące podatków) od nieuprawnionych zapożyczeń. Przyznaję, że często czułem się zmęczony tym, jak raport plagiat.pl „rwał” tekst na strzępy i trzeba było sprawdzać, czy jego wskazania są tylko przypadkowymi podobieństwami, czy podobieństwo jest głębsze. Nigdy jednak nie miałem kłopotu z zauważeniem podobieństwa wskazywanego przez plagiat.pl, bardzo często było ono nieznaczące, ale że podobieństwo było, nie dało się zaprzeczyć. Nierzadko też z pozoru nieznaczące podobieństwo wskazywane przez plagiat.pl okazywało się jednak poważną nieuczciwością. Doświadczenie nauczyło mnie – o ile jestem w stanie zwerbalizować – że najważniejsze są a) kilka nawet krótkich i z pozoru nieznaczących fraz w jednym akapicie podobnych do jednego innego tekstu, b) istnienie w danym wskazaniu podobieństwa orzeczeń (system działa tak, że fragmenty tekstu, które rozpoznaje jako podobne, podświetla pogrubieniem i innym kolorem czcionki) oraz c) kropki w środku takiego podświetlenia. Zwłaszcza ten ostatni przypadek wyklucza, że coś jest terminem i daje niemal stuprocentową pewność, że coś zostało skopiowane skądinąd.
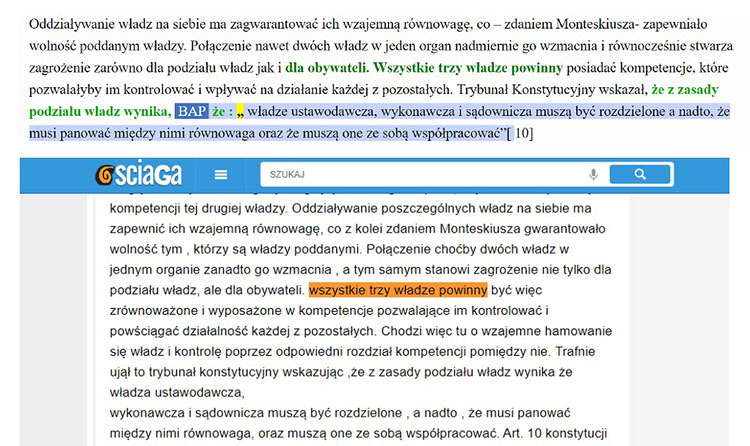
Przykład widzimy na rys. 1. W górnej części obrazka możemy zobaczyć, jak wygląda fragment raportu plagiat.pl, w dolnej widzimy stronę internetową wskazywaną przez ten system. Możemy tu łatwo zauważyć, że choć system wskazał stosunkowo krótką frazę („dla obywateli. Wszystkie trzy władze powinny”), to realne podobieństwo okazuje się rozmiarów akapitu. Nie trzeba tu przeprowadzać dowodu, że autor tej pracy dyplomowej dokonał nieuprawnionego zapożyczenia, żeby jednak je dostrzec, wymagana jest pewna dociekliwość. By po tak błahym z pozoru śladzie dojść do tego, że skopiowany został cały akapit, trzeba otworzyć wskazywaną przez system stronę internetową, zlokalizować podobną frazę i sprawdzić, czy podobieństwo nie jest większe niż samo podświetlenie.
Pewnym kłopotem związanym z raportami plagiat.pl było to, że zdarzali się – podkreślmy, na szczęście nieliczni – promotorzy, którzy takiej dociekliwości nie prezentowali, a wręcz prezentować nie chcieli i upierali się, że wskazanie przez system sześciu słów jest przecież nieistotne. Z tego względu, wypełniając sumiennie i zgodnie z wewnętrznymi przepisami swe zadania, musiałem czasem wchodzić w konflikt z promotorami, którzy chcieli mieć kolejną pracę dyplomową z głowy, a ja dowodziłem, że niestety praca nad nią jeszcze się nie skończyła i nie wiadomo, czy w ogóle dojdzie do obrony.
Nowy wspaniały JSA
Z powodu tych czasochłonnych i czasem emocjonujących „spięć”, o skardze do rektora i zarzutach o mobbing i inne niegodziwości nie wspominając (podobne zarzuty spotykają też oczywiście dziekana), w październiku 2018 r. z prawdziwym entuzjazmem przyjąłem wieści o nowym systemie antyplagiatowym, który wprowadzała nowa ustawa, a który przygotowywał Ośrodek Przetwarzania Informacji na zlecenie MNiSW. System ten miał rozpoznawać podobieństwo całych fragmentów w określonym (i możliwym do regulacji) procencie. Z prezentacji wynikało, że nie będzie trzeba już promotorom dowodzić, że krótki fragmencik wskazany przez system to ślad skopiowania całego akapitu, nowy Jednolity System Antyplagiatowy nie będzie tak „rwał” tekstu, jak plagiat.pl. Wracając do przykładowego fragmentu z rys. 1: wyobraziłem sobie, że system, dostrzegając nawet procentowe podobieństwo, nie będzie zwracał uwagi na zamianę „zagwarantować” na „zapewnić” i zmiany szyku, nie będzie tak „rwał” tekstu, nie trzeba będzie dowodzić promotorom, że student coś skopiował z Internetu, bo JSA zaznaczy po prostu od razu cały taki akapit. Dodatkowo JSA będzie wykrywał zmiany stylu, w czytelny sposób pokazywał manipulacje, jakim poddany został tekst i jako bazę porównawczą będzie miał coś, czego nie miał wcześniej żaden inny tego typu system: Ogólnopolskie Repozytorium Pisemnych Prac Dyplomowych (ORPPD), czyli archiwum wszystkich prac, na podstawie których od kilku lat w całej Polsce przyznawane są dyplomy. Praca obroniona w Opolu nie będzie już mogła być broniona po miesiącu w Suwałkach, jak opowiadał dla portalu www.sztucznainteligencja.org.pl dr Marek Kozłowski, jeden z twórców JSA.*
Zawiedzione nie tylko nadzieje
Muszę przyznać, że rozbudziło to moje nadzieje, które w czerwcu 2019 r., po przeanalizowaniu stu kilkudziesięciu raportów podobieństwa JSA, legły w gruzach. Uważam, że JSA jest do niczego i wydaje mi się, że jego problemy są natury fundamentalnej. Ale po kolei.
Zdarzyło mi się już kilkakrotnie korespondować z pracownikami OPI, zgłaszać szereg uwag, proponować pewne rozwiązania i prawie za każdym razem bardzo mi dziękowano i zapewniano, że moje uwagi „zostały przekazywane analitykom”. Ponieważ nie uzyskałem satysfakcjonującej odpowiedzi, a mam podejrzenie, że przez JSA przechodzą prace przynajmniej z błędami cytowania, uważam za stosowne rozpocząć publiczną dyskusję.
Na naszym wydziale zaczęliśmy od współczynnika podobieństwa tekstu na zalecanym przez JSA poziomie 0,3, by dość szybko stwierdzić, że wskazywane podobieństwa nie mają najmniejszego sensu i podnieść go do 0,6, a następnie do 0,8. Przypomnijmy, że współczynnik ten oznacza swoistą czułość sprawdzania – że dwa teksty powinny być do siebie podobne w takim właśnie procencie. Kiedy więc przy czułości osiemdziesięcioprocentowego podobieństwa wskazywane fragmenty nierzadko w ogóle nie były do siebie podobne, napisałem do OPI: „ze względu na specyfikę prac bronionych na wydziale ustawiliśmy współczynnik podobieństwa na poziomie 0,8, jeśli dobrze rozumiem, system w takim razie powinien wskazywać fragmenty, których kolekcje wyrazów [chodzi o to, że ich kolejność nie ma znaczenia] są identyczne w 80%. Czy system na pewno działa poprawnie? Wskazuje bardzo długie fragmenty, a podobieństwa nie sposób się dopatrzyć ‘na oko’. Proszę bądź o wskazanie takiego podobieństwa we fragmencie 3.1.1 w badaniu nr X, bądź wyjaśnienie, dlaczego system wskazuje te fragmenty jako podobne, ja nie znajduję żadnego punktu zaczepienia”.
Odpowiedź brzmiała: „Wskaźnik 0.8 jest miarą podobieństwa, natomiast nie jest do końca intuicyjny, tzn. jest miarą na wektorowej reprezentacji zdań, więc to nie do końca widać gołym okiem. Fragmenty, o których Pan wspomina, są tak dobrane, ponieważ mają wspólne frazy, np. ‘indywidualne konta zabezpieczenia emerytalnego’”.
W tym samym wątku mojej korespondencji z OPI analityk zalecił podniesienie parametru do poziomu 0,9, co też na wydziale uczyniliśmy, wskutek czego Procentowy Rozmiar Podobieństwa większości prac spadł do przedziału 0-5%. Formalnie musimy więc akceptować bez mała wszystkie prace, niemal do żadnego z raportów do prac sprawdzanych od tego czasu nie można mieć zastrzeżeń. Czy podniesienie współczynnika do wysokiego poziomu 90% „oślepiło” JSA? W znacznym stopniu tak, ale czy wyeliminowało bezsensowne „podobieństwa”? Niestety nie.
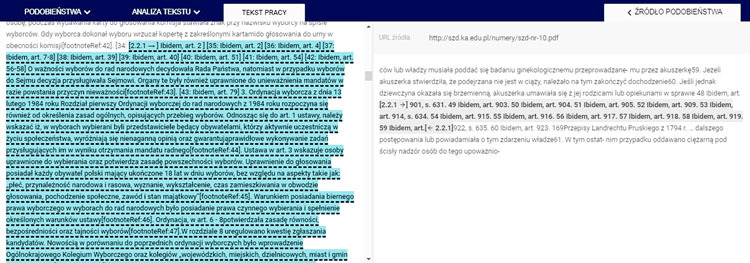
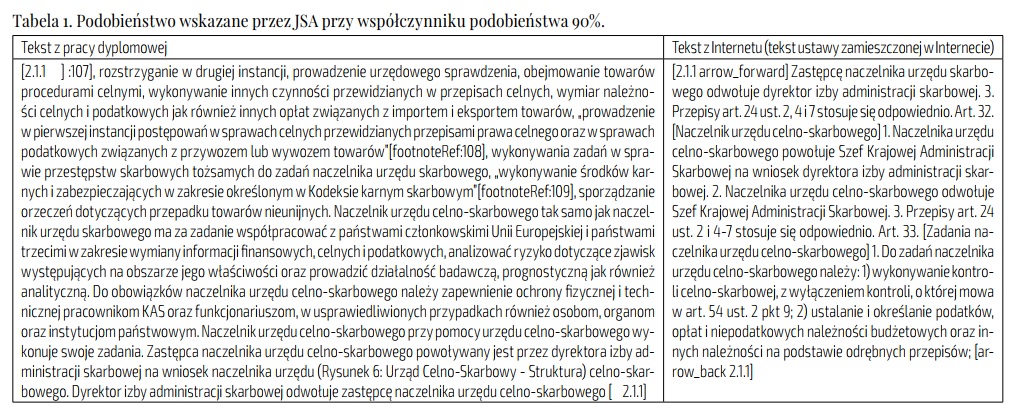
Prezentuję dwa przykłady takiego 90-procentowego podobieństwa, jeden w czytelniejszej formie tabeli (Tabela 1), drugi w formie zrzutu z ekranu (Rys. 2). Na ich podstawie będzie można zdać sobie sprawę z sensowności, czytelności i przydatności takich wskazań.
Na podstawie tych wskazań można zrozumieć moje dość poważne przypuszczenie, że problemem JSA jest chyba właśnie to, co miało być jego główną zaletą – nowy algorytm. W pierwszym przypadku (tabela) od razu widać, że podobieństwo na pewno nie sięga 90%, w drugim (rys. 2) od razu widać, że to jest nieznaczące podobieństwo wytworzone przez ten algorytm. Może to też częściowo wynikać, na co zwracałem uwagę w korespondencji z OPI, z braku objętościowej równowagi między tekstem analizowanym i wskazywanym. System nie mógłby się dopatrzyć 90% podobieństwa tych dwu fragmentów, gdyby były one objętościowo podobne. Dlaczego więc nie ma tej równowagi? Może dlatego, że algorytm JSA oślepłby wtedy zupełnie.
W przypadku raportów plagiat.pl system wskazywał zwykle podobieństwa krótkie i często nieistotne. Wiadomo, system jest tylko systemem, nie orzeka o plagiacie, wskazuje jedynie podobieństwo (niekoniecznie ze źródłem z pierwszej ręki), mówi: to jest podobne do tego. Raporty plagiat.pl wymagały więc interpretacji promotora lub – jak na naszym wydziale – administratora, który uznawał wskazania za nieistotne (bo to nazwy ustaw, bo to tytuły książek, bo to poprawnie oznaczone cytowania itd.), ale nie sposób było zaprzeczyć podobieństwu wskazywanych przez plagiat.pl fragmentów. Plagiat.pl więc w jednym akapicie podświetlał niewiele kilku- bądź kilkunastowyrazowych fragmentów, i klikając w poszczególne podświetlenia można się było przekonać, że wszystkie one wskazują jeden i ten sam tekst Z. Można było otworzyć sobie tekst Z i „na piechotę” znaleźć punkt zaczepienia, szukając podświetlonej frazy (ctrl+f) i sprawdzając, czy zdania poprzedzające i następujące są tekstowo lub semantycznie podobne do tekstu sprawdzanej pracy. Takie rozwiązanie, jak pokazałem na przykładzie z rys. 1, mimo szczątkowych zdawałoby się wskazań podobieństwa, pozwalało dość szybko stwierdzić, że tych kilka akapitów zostało przez studenta skradzionych z takiego a takiego tekstu. Okazuje się, że „rwanie” tekstu przez plagiat.pl jest jego zaletą, o tyle że stwierdzenie nieistotności danego wskazania jest względnie łatwe – dzięki krótkości wskazywanych fragmentów można to zrobić szybko „gołym okiem”.
Zaletą JSA miało być natomiast to, że rozpoznaje on podobieństwo większych fragmentów nawet wtedy, gdy tekst będzie podobny do innego w jakimś procencie. W przekonującej teorii miało to być i wygodniejsze, i skuteczniejsze. Wygodniejsze, gdyż z daleka miało być widoczne podobieństwo całego dużego fragmentu, nie zaś kilku krótszych fraz, skuteczniejsze, gdyż wykrywanie nawet procentowego podobieństwa miało automatycznie wykrywać zmiany w danym fragmencie, których studenci często się dopuszczają: strony czynnej na bierną, poszczególnych wyrazów na synonimy itd. W praktyce jednak jest to rozwiązanie JSA nie tylko niebywale uciążliwe dla analizującego raport, ale i – jak się wydaje – zdecydowanie mniej skuteczne.
Problem JSA nie polega bowiem jedynie na zaprezentowanym już „dorabianiu” podobieństwa tam, gdzie go nie ma, bo to tylko powoduje uciążliwość dla analizującego raport. Największy problem tkwi w tym, czego JSA nie widzi (i na moje oko jest to związane nie tylko z różnymi bazami porównawczymi obu systemów, ale właśnie z algorytmem). Kiedy analizowałem kolejne raporty JSA, moje doświadczenie podpowiadało mi, że nieproporcjonalnie mało wskazań JSA dotyczy zawartości Internetu. A to jest przecież główne źródło „inspiracji” studentów. Postanowiłem więc to sprawdzić. Dzięki uprzejmości firmy platiat.pl nieodpłatnie sprawdziłem dziesięć prac równolegle w JSA i plagiat.pl; było to jeszcze przy współczynniku 0,6 dla JSA. W tym porównawczym teście nie chodziło mi o to, żeby znaleźć błędy cytowania, ale żeby sprawdzić, co który system widzi, a czego nie widzi (zwracałem więc uwagę również na poprawnie oznaczone cytowania). Nie było więc dla mnie najistotniejsze, czy dany fragment rozpoznany jako podobny do innego tekstu został przez studenta poprawnie oznaczony, czy nie. Moje przypuszczenia się potwierdziły, JSA praktycznie nie widzi zapożyczeń z Internetu.
W tej małej próbie przypadkowo wybranych prac trafiła się jednak jedna (praca Y), co do której można było mieć poważniejsze zastrzeżenia: PRP wskazany przez JSA wyniósł 38% przy współczynniku podobieństwa 60%, większość wskazań JSA była jednak nieistotna i przypadkowa, jak wyżej zaprezentowane, a wskazania podobieństwa do zawartości Internetu ograniczały się w zasadzie do nazw aktów prawnych i zapisów bibliograficznych. To są tego typu wskazania, że jeśli promotor nie będzie się wdawał w zbytnie szczegóły, taki raport bez większych zastrzeżeń zaakceptuje. Dwa krótkie przykłady z takimi błędami cytowania lepiej zobrazują jednak, jak poważne skutki może mieć nieskuteczność JSA.
Przykład nr 1 z pracy Y
W pracy Y, w której niedbale używane cudzysłowy (moje doświadczenie podpowiada, że taka niedbałość jest często zamierzona) nie pozwalają na określenie granic cytatu, nadużyty jest jeden cytat, który system plagiat.pl podświetla jak na Rys. 3. Jak wygląda tekst na wskazywanej przez plagiat.pl stronie internetowej, pokazuje zaś Rys. 4.
Podobieństwo jest łatwo uchwytne gołym okiem, akapit, który nie został przez system podświetlony, pochodzi prawdopodobnie z pełnej wersji artykułu, który dostępny jest po zalogowaniu.
Co w tym samym miejscu wykrywa JSA? Zupełnie nic. Nie tylko nie zauważył podobieństwa, ale i zmiany stylu, co miało być tak wielką przewagą JSA nad wcześniejszymi systemami (patrz Rys. 5).
Na marginesie zwróćmy też uwagę, o ile czytelniejsze są podświetlenia fragmentów faktycznie podobnych w raporcie, który dzieli tekst na coś w rodzaju akapitów, o ile łatwiej wychwycić podobieństwo gołym okiem, jeśli treść przypisów (zawierających zwykle nieistotne dla analizy antyplagiatowej zapisy bibliograficzne) jest przeniesiona na koniec raportu (jak robi to plagiat.pl), niż gdy treść przypisów wkładana jest do tekstu głównego w kwadratowych nawiasach (jak robi to JSA).
Przykład nr 2 z pracy Y
Porównajmy wskazania plagiatu.pl w raporcie do pracy Y (Rys. 6) i stronę internetową wskazywaną przez system (Rys. 7).
Jak łatwo zauważyć, jest to typowe „pomylenie” cytowania z odwołaniem. Niby przypis jest, ale cudzysłów się zgubił. Gdyby to było odwołanie, byłoby w porządku, ale to jest cytat, który powinien się znaleźć w cudzysłowie. Jest to rażący błąd cytowania, wbrew pozorom błąd często celowy. Jak wygląda wskazanie JSA do tego fragmentu?
JSA wskazuje w tym miejscu (Rys. 8) zupełnie nieznaczące „podobieństwo” – w większości bibliograficzne - w postaci obszernego fragmentu, którego objętość może czytelnik ocenić po wymiarze suwaka po prawej stronie obrazu nr 8 – JSA wskazuje inny tekst z ORPPD.
Podsumowanie
Nieskuteczność JSA wynika prawdopodobnie z algorytmu, który dorabia podobieństwo tam, gdzie go nie ma. Zbyt długie wskazania sprawiają, że weryfikowanie takich pomyłek systemu przez człowieka jest niesłychanie uciążliwe. JSA nie widzi też często podobieństwa tam, gdzie ono występuje, zwłaszcza jeśli jest to podobieństwo do zawartości Internetu (a jeśli już je widzi, to zwykle w sposób nieistotny).
Wniosek z moich dotychczasowych doświadczeń z systemami plagiat.pl i JSA oraz z analizy na małej próbie dziesięciu prac jest taki, że JSA nie spełnia funkcji, do której został stworzony, a którą już powinien pełnić. Zachęcam analityków JSA do publicznej odpowiedzi, a przedstawicieli ministerstwa do weryfikacji moich twierdzeń na większej próbie prac równolegle różnymi systemami antyplagiatowymi, a w razie potwierdzenia moich spostrzeżeń do podjęcia adekwatnych działań w skali kraju. Możliwe, że trzeba będzie post factum sprawdzać inaczej niż w JSA prace, na podstawie których w lipcu br. zostaną nadane dyplomy, i w razie stwierdzenia plagiatu te dyplomy odbierać. Sprawa jest w każdym razie zbyt poważna, by można ją było, jak wiele innych, przemilczeć.
* Te piękne opowieści można znaleźć m.in. w wywiadzie przeprowadzonym z Markiem Kozłowskim przez Roberta Siewiorka: Łowca klonów, tropiciel parafraz, https://www.sztucznainteligencja.org.pl/lowca-klonow-tropiciel-parafraz/, dostęp 16.06.2019. Na marginesie trzeba zauważyć, że nie jest to prawdą, bo od obrony pracy dyplomowej do momentu, kiedy trafi ona do ORPPD mijają czasem ponoć i trzy miesiące, w tym czasie JSA nie będzie więc w stanie jeszcze zauważyć podobieństwa.







Dodaj komentarz
Komentarze